Work Report
Mriganka Basu Roy Chowdhury
What we wanted to do
- Sprinklr has a few places where auto-completion can be useful.
- One example would be the new News Stories feature.
- A user can search for, say,
covid india. - Currently, it displays articles which have
covidorindia, suitably weighted by occurence positions (title/body etc.)
Need something that:
- Suggests more tags:
covid india→covid india cases - Also corrects mistakes:
cvd→covid - Completes words:
ind→india.
auto-suggest
Demo
How it works
- Has 3 major components
Fuzzy Corrector,Word Completer,Tag Suggestor.- Exposed as a REST API.
- Which can be fed lists of strings.
- And can be used to complete/correct phrases.
Preprocessing
- Remove words of little content, like “if”, “so”, “a” etc. Eg. “saw cat jump over fence” from “i saw a cat jump over the fence”.
- Standardize quotes, punctuation etc – was a bug earlier.
- Pick \(\leq k\) -letter combinations from these words, in order, as phrases. \(k = 3\) by default.
- Each string has a quota of the number of phrases, set to ~50 by default.
- Pick random phrases of length \(k + 1\) till we exhaust this quota.
Fuzzy Corrector
- Converts words into a phonetic representation.
- A representation of how it sounds.
- Currently using
Soundex. - This can convert “Donald” → “D543”. Also “Dnald” → “D543”.
- When we need to correct a word, just return the top words that sound the same.
- So missing out vowels has no effect, and can be fixed.
- Also consonants that don’t make much of a difference.
Word Completer
- Uses a trie for completing words
- Each node also stores how many times it has been visited (popularity)
- And also the top few completions (i.e. most popular descendants in the trie).
Tag Suggestor
- Maintains a trie, where each edge is a word.
- We insert phrases (short ordered sublists of sentences in input) into the trie.
- Given some words, it tries to find the best completions using this trie.
- Also tries deleting some words from the phrase before doing the above.
- Ranking is decided by the “importance” of the subphrase that is being completed.
Data Storage
- Currently using an in-memory Guava Cache of ~ 2 GB size.
- And a Mongo store, which persists all keys.
- Mongo persistence task runs out of the main thread.
- All important keys that are not found in the cache are reloaded once found in Mongo.
- So, repeated similar queries take little time after the first.
Dependency Diagram
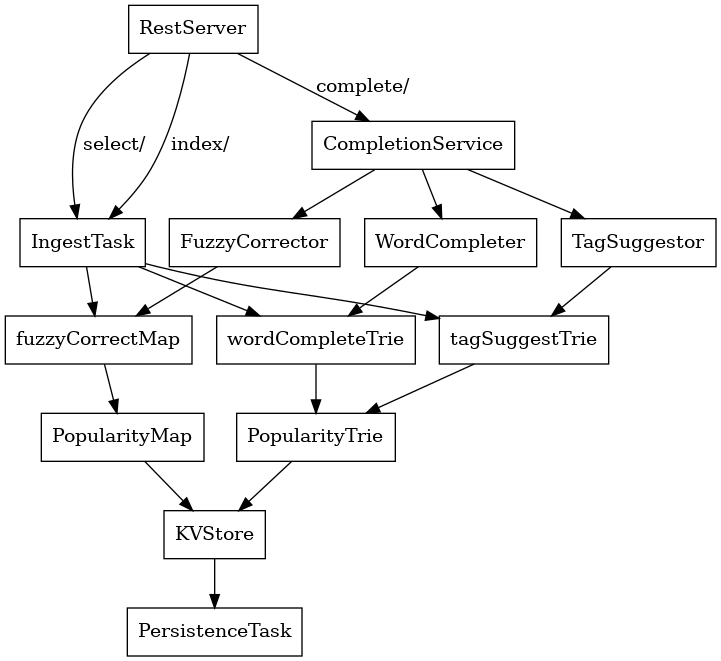
Characteristics
Test Set
- Contains a few tests for checking accuracy.
- A 10000 + 10000 set of news titles in English
- A 100 set of news titles in other languages like Russian and Spanish to check Unicode support.
- These are fed to the system via the
index/route.
Performance
- All tests are on my computer (8 GB / i5 8th), with the initial version of the code. Can be found at https://github.com/mbrc12/auto-suggest (
redisless-tagsbranch) - Around 2 - 2.5 minutes to index a 10000 set.
- Completion latency is 30 ms on average
- Under a complete restart, the latency goes upto ~100 ms at first, but drops as the cache starts filling up.
- Cache can hold 10-15 days worth of data in memory itself.
Further Work
Phrase completions
- Right now, we suggest only tags.
- But, it is also possible to complete phrases, like Gmail does in email composition.
- A preliminary version is implemented in the above repository in
multi-langandphrase-suggestbranches.
Fuzzy Correction - I:
- An useful improvement would be to fuzzy correct words of other languages like Japanese or Spanish.
- Under my current approach, this requires phonetic content algorithms of other languages. This is a relatively under-developed area.
- Edit distance approaches do not work in Japanese for example, because Kanji characters represent a word/idea, as opposed to a sound like in English.
- It also doesn’t work well in English, as it is insensitive to meanings. Words with small edit distance mean vastly unrelated things,
nightandright.
Fuzzy Correction - II:
- In English, it might be possible to do better suggestions using Soundex alone.
- The idea is to change a few characters in the Soundex representation itself.
- However, this will:
- Increase latency
- And if wrong characters are substituted, the suggested words might be useless.
Other Projects
- Some projects on Spring and Patterns in Java.
- An application that fetches titles (concurrently) from https://newsriver.io and pushes them to Kafka, and consumed on the other side by a (concurrent) consumer.
Thanks
- Thanks to Tejasv Gupta for being available throughout the duration and guiding us in every step. And also for suggesting such an interesting problem!
- Also thanks to Shubham and Sudhanshu for some really interesting discussions.
- Finally, thanks to Sprinklr for organizing this wonderful internship.